Come semplificare l’incident management
Una gestione degli incident organizzata ed efficiente è essenziale per ripristinare velocemente i servizi IT riducendo al minimo l'impatto sulle operazioni aziendali. Il segreto è una soluzione ITSM.

La gestione degli incidenti, o incident management, è un elemento cruciale per qualsiasi azienda o organizzazione e può fare la differenza tra la soddisfazione del cliente e la perdita di fiducia.
Tuttavia, gestire e coordinare gli incidenti può essere complesso, soprattutto se per farlo si utilizzano molti strumenti differenti e non connessi tra loro.
Cos’è un incident?
Secondo il framework ITIL (Information Technology Infrastructure Library), un “incidente” è un evento non pianificato che causa o può causare interruzioni o riduzioni delle prestazioni dei servizi IT.
Gli incidenti rappresentano situazioni in cui un servizio, un sistema o un’applicazione non funziona come previsto o si verifica un’interruzione del servizio. Il normale funzionamento dei servizi IT è compromesso e ciò causa disagi agli utenti finali o compromettendo l’erogazione dei servizi stessi.
Questi incident possono includere:
- Problemi software: Errori, bug o malfunzionamenti di software o applicazioni.
- Malfunzionamenti hardware: Guasti hardware su computer, server, dispositivi di rete, etc.
- Interruzioni dei servizi di rete: la perdita di connessione Internet o il non funzionamento della posta elettronica.
- Problemi di sicurezza: Attacchi informatici, violazioni della sicurezza o accessi non autorizzati ai dati sensibili.

Incident vs Request: facciamo chiarezza
Una richiesta non è sempre un problema. E un problema non è sempre una richiesta.
Un incident è qualcosa che non funziona: la stampante si blocca, il software dà errore, l’e-mail non parte. Un service request, invece, è una richiesta normale: nuovo account, installazione di un programma, reset di una password.
Se non distingui bene le due cose, il team IT perde tempo. Le priorità si confondono. Le automazioni smettono di funzionare come dovrebbero.
Se usi una piattaforma ITSM, ti tornerà molto utile definire chiaramente le due categorie. Così facendo, aiuterai gli utenti a scegliere la categoria più adatta.
Perché l’incident management è importante
Un problema lato IT blocca un’attività. Se non viene risolto in fretta, tutto si ferma. E quando le cose si fermano, l’azienda perde tempo, soldi e spesso anche la fiducia dei clienti.
Gestire bene un incident vuol dire: ridurre al minimo i danni. Se il team IT sa cosa fare e lo fa in fretta, l’impatto sull’azienda si riduce. Il lavoro riparte. Le persone non restano bloccate.
L’incident management serve a questo. Ti permette di agire subito, e limitare i danni. Ti aiuta a risolvere i problemi, ma anche a prevenirli.
Non serve avere mille strumenti diversi. Basta un processo chiaro e un sistema che ti permetta di gestire tutto in modo centralizzato. E serve anche che chi lavora sul problema sappia dove mettere le mani.
Qual è il processo migliore per l’incident management?
Il processo di incident management in ITIL è progettato per gestire questi eventi in modo da ripristinare i servizi IT nel minor tempo possibile.
Le fasi principali del processo sono le seguenti:
1. Rilevazione e registrazione dell’incidente: E’ necessario identificare e registrare l’incidente documentando i dettagli dell’evento, inclusi tempi di disservizio, categoria, impatto e priorità.
2. Classificazione e assegnazione dell’incidente: Serve classificare l’incidente in base alla sua gravità e assegnarlo al team o alla persona responsabile per la risoluzione.
3. Diagnosi e risoluzione dell’incidente: Indagare sulle cause dell’incidente e lavorare per risolverlo. Questa fase coinvolge l’analisi del problema, l’implementazione di soluzioni temporanee o definitive e il ripristino del servizio al suo stato operativo normale.
4. Chiusura dell’incidente: Una volta risolto, l’incidente viene chiuso e viene fornita documentazione dettagliata sulle azioni intraprese e sulle soluzioni adottate.

Best practice per la gestione degli incidenti
Puoi avere un buon sistema, ma se lo usi male, i risultati non arrivano. Ecco alcune buone pratiche:
Migliora, sempre. Guarda i numeri, leggi i feedback e cambia quello che non funziona. Non aspettare che gli stessi errori si ripetano.
Scrivi tutto. Ogni ticket deve essere tracciabile. Chiunque lo prenda in mano deve capire cosa è successo, chi ci ha lavorato e cosa è stato fatto.
Classifica bene. Non tutto è urgente. E non tutto va al tecnico senior. Usa categorie e priorità in modo sensato.
Assegna con criterio. Un incident finisce alla persona giusta solo se il sistema lo riconosce. Usa regole di assegnazione chiare.
Automatizza solo dove necessario. Le automazioni sono utili, ma non devono diventare una scatola nera. Cerca di mantenerne il controllo.
Forma il team. Un buon tool non basta. Servono persone che sappiano usarlo e che sappiano gestire le situazioni, non solo i software.
Chiudi con ordine. Ogni ticket risolto deve avere un resoconto chiaro. Se tornerà utile in futuro, dev’essere leggibile anche da chi non lo ha gestito direttamente.
Nella pratica, come puoi semplificare l’incident management?
l’incident Management IT richiede una serie di passaggi pratici per garantire che le segnalazioni vengano ricevute, registrate, assegnate e risolte in modo tempestivo e accurato.
Ecco un processo pratico per gestire le richieste IT:
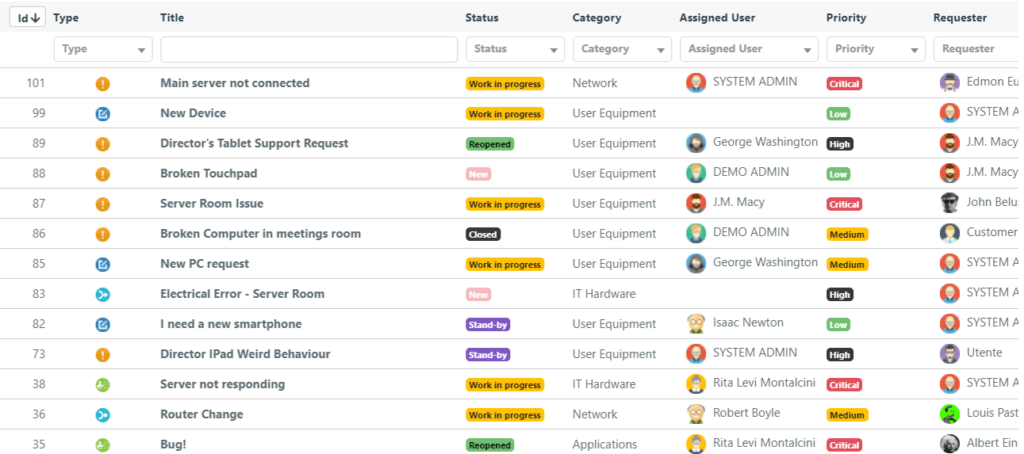
1. Adotta un sistema di ticketing centralizzato
Utilizza un sistema di ticketing o, meglio ancora, una piattaforma ITSM (IT Service Management) per registrare, tracciare e gestire tutte le segnalazioni (ticket). Questo sistema deve poter consentire agli utenti di inviare segnalazioni in modo chiaro e strutturato.
2. Registra le richieste in modo completo
Assicurati che ogni segnalazione contenga informazioni dettagliate e rilevanti. Un modulo di richiesta ben strutturato dovrebbe includere dettagli come il nome dell’utente, la descrizione del problema, la priorità e altri dettagli specifici per poter risolvere il ticket.
3. Classifica e assegna i ticket
Classifica i ticket in base alla loro priorità, gravità, tipologia e impatto sulle operazioni. Se definisci le categorie in modo chiaro puoi indirizzare le richieste al team o al tecnico più appropriato per una risoluzione rapida.
4. Definisci ruoli e responsabilità
Una chiara definizione dei ruoli ed assegnazione delle responsabilità all’interno del team IT ti aiuta a far sì che ogni ticket venga gestito da personale competente; inoltre eviti sovrapposizioni di compiti e ritardi nella risoluzione degli incidenti.
5. Gestisci i tempi di risoluzione
Configura SLA specifici per ciascuna tipologia di incidenti per rispettare le metriche di servizio stabilite. Individua obiettivi di tempo realistici per la risoluzione delle richieste in base alla loro priorità. Assicurati che i tecnici seguano questi tempi e che venga data la giusta attenzione alle richieste più urgenti.

6. Comunica in modo trasparente
Tieni aggiornato lo stato delle richieste nel sistema di ticketing. Invia notifiche automatiche agli utenti riguardo gli aggiornamenti del ticket, le stime di risoluzione e qualsiasi altra informazione rilevante.
7. Automatizza le attività ripetitive
Utilizza una soluzione ITSM avanzata per creare flussi di lavoro automatizzati e gestire automaticamente le attività ripetitive. Automatizza la gestione delle richieste in base a determinati criteri, crea risposte automatiche per confermare la ricezione delle richieste o aggiornare gli utenti sullo stato di avanzamento del ticket. Ciò riduce il tempo dedicato alle attività di routine e accelera i tempi di risposta.
8. Monitora il servizio
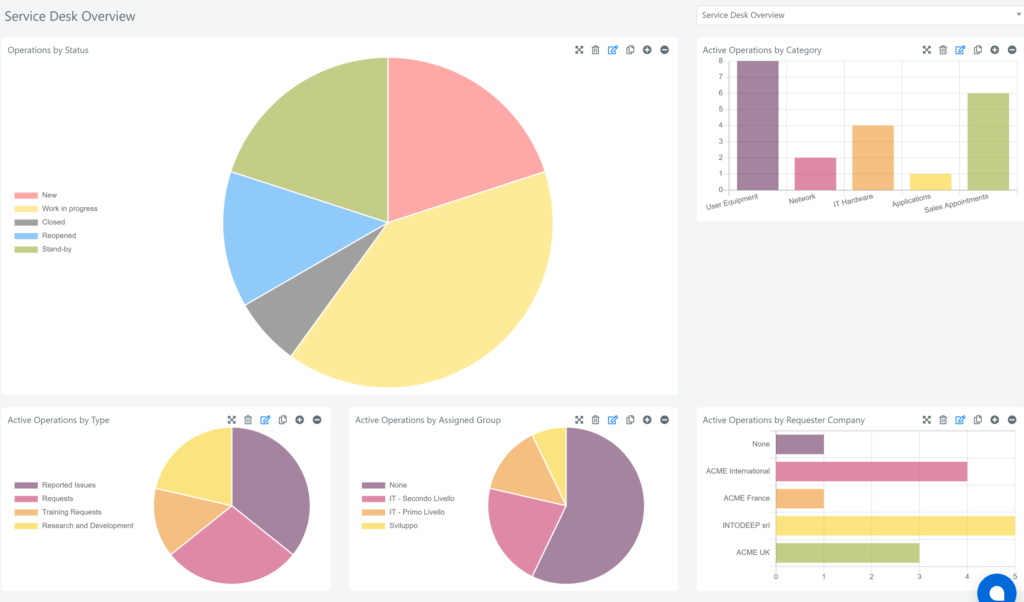
Traccia le metriche chiave (KPI), come il tempo medio di risoluzione, la soddisfazione dell’utente e il numero di richieste risolte, e utilizzale per valutare l’efficienza dei processi e identificare possibili aree di miglioramento.
9. Raccogli feedback
Utilizza feedback dagli utenti e dal team per apportare costantemente miglioramenti, aggiornando procedure, flussi di lavoro e strumenti in base alle esigenze.
10. Il ruolo della knowledge base per l’incident management
Molti incident si presentano con gli stessi sintomi e richiedono sempre le stesse soluzioni. Se ogni volta il team IT affronta il problema da capo, il tempo perso si accumula rapidamente e l’efficienza ne risente.
Una knowledge base serve proprio a questo: ridurre il lavoro ripetitivo, permettendo agli utenti di trovare da soli le risposte ai problemi più comuni. Allo stesso tempo, anche il team tecnico può consultare soluzioni già testate, evitando di reinventare la ruota.
Quando la knowledge base è integrata nel sistema di ticketing, diventa ancora più utile. Durante la creazione di una richiesta, l’utente può visualizzare in automatico gli articoli più pertinenti rispetto al problema che sta segnalando. Se trova la risposta, non invia nemmeno il ticket, alleggerendo il carico sul supporto.
Per funzionare davvero, però, va mantenuta aggiornata. Ogni volta che un nuovo problema viene risolto, è importante documentarlo in modo chiaro. Più contenuti rilevanti ci sono, più aumenta l’autonomia degli utenti e più diminuisce il numero di richieste da gestire.

Errori comuni
Anche quando il processo è ben strutturato, ci sono errori che tendono a ripetersi e che, nel tempo, compromettono l’efficacia dell’incident management. Riconoscerli e correggerli aiuta a mantenere il servizio efficiente e a evitare rallentamenti evitabili.
Uno dei problemi più comuni sono le descrizioni vaghe. Un messaggio come “non funziona il PC” non dice nulla di utile. Serve che l’utente spieghi cosa succede, in quale momento, e con quali effetti. Una segnalazione chiara accelera la diagnosi e riduce i passaggi inutili.
Un altro errore frequente riguarda i ticket duplicati. Se più persone segnalano lo stesso problema, occorre accorpare le richieste per evitare confusione e disperdere risorse.
C’è poi la mancanza di follow-up. Chiudere un ticket appena si applica una soluzione può sembrare efficiente, ma se non si verifica che il problema sia davvero risolto, il rischio è che la richiesta torni indietro.
Anche la gestione delle priorità può essere un punto debole. Quando tutto viene trattato come urgente, diventa difficile capire cosa gestire prima. Servono criteri chiari per valutare impatto e urgenza.
Infine, spesso manca una documentazione adeguata. Se un problema viene risolto ma non viene registrato come è stato fatto, la stessa situazione richiederà lo stesso tempo anche in futuro. Documentare non è un passaggio secondario: è parte del lavoro.
Correggere questi errori richiede attenzione, ma fa la differenza tra un team reattivo e uno davvero efficace.
Quale strumento hai a disposizione per l’incident management?
L’obiettivo principale è essere rapidi nel ripristinare i servizi IT, riducendo al minimo il disagio per gli utenti e l’impatto sulle operazioni aziendali. L’utilizzo di un software Help Desk facilita notevolmente la gestione degli incident IT e ti permette di migliorare il servizio offerto.
Deepser è il software Help Desk italiano all-in-one grazie al quale puoi ricevere, tracciare e categorizzare i ticket. Ed offre molto di più!
Le diverse funzionalità della piattaforma ti permettono di automatizzare le attività ripetitive, digitalizzare i flussi di lavoro e comunicare velocemente con gli utenti ed i colleghi. Puoi inoltre creare un inventario completo degli asset IT e monitorarne lo stato in modo automatico.
Scopri come i nostri clienti hanno migliorato le performance aziendali ed il servizio offerto ai propri utenti adottando Deepser per gestire gli incident.
Clicca qui e leggi il caso d’uso di un’azienda che offre efficacemente supporto IT ai propri utenti distribuiti su più sedi.